Training on Detectron2 with a Validation set, and plot loss on it to avoid overfitting
tldr: you can just jump to the code here: https://gist.github.com/ortegatron/c0dad15e49c2b74de8bb09a5615d9f6b
I’ve been using Detectron2 for some time now and found it very nice to quickly test how inference on different already trained models perform for my data. With Detectron2, it’s very easy to switch between models for Object Detection, Mask Segmentation, Panoptic Segmentation, etc.
When it comes to training, Detectron2 proves to be good too, and it’s easy to define a new dataset for your own data and train with it, either starting from scratch or doing transfer learning.
But when training, I quickly found that some things I thought were going to be provided out-of-the-box just weren’t, and I had to code them myself. Of course, adding functionality to quite a complex platform as Detectron2 is requires some time diving through the code and looping your eyes around its files and functions, so here I will try to make it easier for you :)
Split Dataset Test/Train/Validation
When training a Machine Learning model, the whole data is split on a Train set and a Test one. Because we want the Test dataset to be locked down on a coffre until we are confident enough about our trained model, we do another division and split a Validation set out of the Train one. Generally, we end up with three datasets: Train being 60% of the whole, 20% for Validation and 20% for Test.
On some other ML libraries like Scikit-Learn, there are some functions you can use that split the datasets at random for you. This is not the case with Detectron2, and you have to make the division by yourself.
So just separate the data, and then register a different dataset for each one of your splits. That’s not hard to do an there are plenty of examples out there, but just remember you will have to register the same Metadata for all of them.
Accuracy on Validation while training
We usually want to compare how well is the model performing on the Validation set WHILE training, to know when are we at risk of overfitting the model to the training data. This is the standard chart you will see on many papers and training examples:

On Detectron2, the default way to achieve this is by setting a EVAL_PERIOD value on the configuration:
cfg = get_cfg()
cfg.DATASETS.TEST = ("your-validation-set",)
cfg.TEST.EVAL_PERIOD = 100This will do evaluation once after 100 iterations on the cfg.DATASETS.TEST, which should be our Validation set. Note that even if the configuration calls it as “Test”, this should actually be the Validation one, or we will be breaking the locks of the Test coffre ;).
But, what exactly is this evaluation?
As documentation says:
“Evaluation is a process that takes a number of inputs/outputs pairs and aggregate them.
This is done by subclasses of DatasetEvaluatorthat process pairs on inputs/outputs of the model, and then aggregates them to return a meaningful results about how did it perform. When setting EVAL_PERIOD, the Evaluator is called with the whole Validation dataset, and the result is then written to the storage.
You can write a custom DatasetEvaluatorfor your model, or if you are training on a standard dataset, Detectron2 offers you many already implemented ones: COCO, LVIS, etc.
Because I’m training with a COCO object detection dataset, I have defined my own trainer to use the COCOEvaluator:
class MyTrainer(DefaultTrainer):
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR,"inference")
return COCOEvaluator(dataset_name, cfg, True, output_folder)
When training, once after EVAL_PERIOD=100 steps the whole Validation set is going to be evaluated and the metrics written on TensorBoard on the label ‘bbox’:
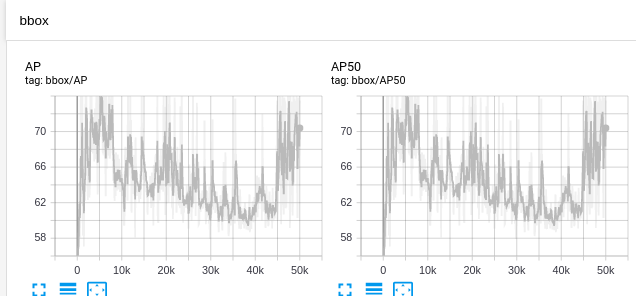
The COCOEvaluator gives metrics like AP for each class, APm, etc. It’s good, but when we train we usually see the progress of our model on terms of the loss value. Monitoring the AP on the evaluator is a good idea, but comparing loss on the Training set to AP on the Evaluation is like comparring peachs to lemons, so…
what if we want to know the loss on the validation set?
The EVAL_PERIOD config is only going to call COCOEvaluator, so if we want to evaluate the loss we need to implement it ourselves, adding the following:
1- Add a custom Hook to the Trainer that gets called after EVAL_PERIOD steps
2- When the Hook is called, do inference on the whole Evaluation dataset
3-Every time inference is done, get the loss on the same way it’s done when training, and store the mean value for all the dataset.
A Hook is a function called on each step, we can add a Hook to our Trainer over writting the metod build_hooks like this:
def build_hooks(self):
hooks = super().build_hooks()
hooks.insert(-1,LossEvalHook(
cfg.TEST.EVAL_PERIOD,
self.model,
build_detection_test_loader(
self.cfg,
self.cfg.DATASETS.TEST[0],
DatasetMapper(self.cfg,True)
)
))
return hooksHere we are constructing a new LossEvalHook (we will define it next), with arguments being the same EVAL_PERIOD config number, the model used for inference, and creating the loader for Validation set.
Next we need to implement LossEvalHook, doing two things:
- Doing inference of dataset like an Evaluator does
- Get the loss metric like the trainer does
So we need to mostly copy and integrate the code from detectron2/evaluation/evaluator.py and the one from detectron2/engine/train_loop.py, and put them together on the LossEvalHook, like this:
(code is too long to write here so check inside the gist)
And that’s it! When we train with that Trainer, we will see the loss on Validation is added to the TensorBoard plots:
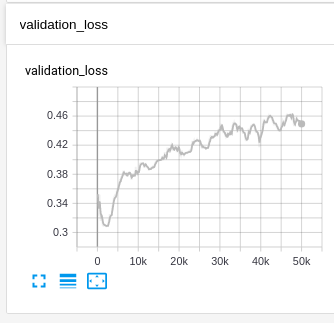
This, together with the AP metrics on Validation we already have, is going to give us good insights about how the training is going and whether is time to stop it or not.
Sadly, TensorBoard will treat this metrics as two separate one, and won’t let us plot them on the same graph. So if we want to
Plot the Train/Validation loss together
we need to set it up by ourselves too:
(please check code for complete one)
plt.rcParams['figure.figsize'] = [15, 8]
plt.plot(
[x['iteration'] for x in experiment_metrics],
[x['total_loss'] for x in experiment_metrics])
plt.plot(
[x['iteration'] for x in experiment_metrics if 'validation_loss' in x],
[x['validation_loss'] for x in experiment_metrics if 'validation_loss' in x])
plt.legend(['total_loss', 'validation_loss'], loc='upper left')It will plot them together, making it easier to compare:
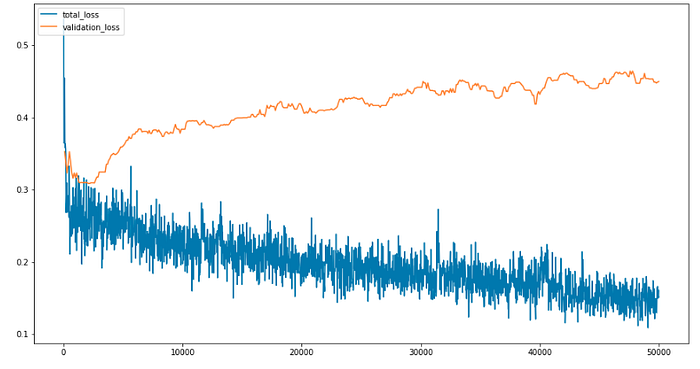
In this case, seems the model is just overfitting after the iteration number 2000, but remember to have a look at the AP too!
Hope you find it useful!
We are eidos.ai, a Computer Vision development team willing. We work with startups helping them to integrate the latest technologies into their business. Check our website at https://eidos.ai or contact us at info@eidos.ai!
